


Gli studi di Lorenz, negli anni ’60, hanno portato alla luce il fatto che l’atmosfera, essendo un sistema dinamico non lineare, ha un comportamento caotico e quindi ha un limite finito di predicibilità. Ciò significa che anche attraverso l’utilizzo di un modello fisico-matematico esatto non è possibile fare una previsione perfetta nel tempo. E’ infatti caratteristica fondamentale dei sistemi dinamici caotici la dipendenza dallo stato iniziale: date due condizioni iniziali infinitamente simili, il sistema (atmosfera) evolve in modi differenti e a tempi lunghi si otterranno due situazioni completamente diverse. Quindi l’approssimazione con cui conosciamo, attraverso le misure, lo stato attuale dell’atmosfera preclude, a prescindere dal modello utilizzato, ogni possibilità di avere previsioni perfette a tempi infiniti.
Famoso ed intrigante è il paradosso del battito d’ali della farfalla che lo stesso Lorenz propose durante un convegno: egli si domandò se il battito d’ali di una farfalla in Brasile potesse provocare un tornado in Texas. La questione è una pura provocazione, per quanto possa essere una effettiva conseguenza in un sistema caotico: se anche ciò fosse vero, altre farfalle nel mondo potrebbero avere l’effetto contrario e in tal caso l’atmosfera sarebbe realmente e completamente impredicibile. Ma questo paradosso, noto come “The batterfly effect”, vuole comunque mettere in evidenza la limitata predicibilità dell’atmosfera che lo stesso Lorenz fissò, con un po’ di pessimismo, a due settimane, pur tenendo conto del fatto che in particolari situazioni questo limite è soggetto a variazioni. Come ben sappiamo, infatti, ci sono situazioni in cui le previsioni sono buone anche per tempi lunghi, altre in cui i modelli perdono affidabilità già dopo pochi giorni.
Quello che divenne evidente dagli studi di Lorenz è il fatto che non ha molto senso parlare di previsione deterministica, cioè di una singola previsione che parte da una analisi iniziale e attraverso un modello determina gli stati futuri. Piuttosto bisogna tenere in considerazione l’incertezza nella conoscenza della condizione iniziale, da cui consegue un comportamento stocastico dell’atmosfera.
Entrano così in gioco le ensemble forecast: anziché affidarsi ad una singola previsione deterministica, si considerano diverse previsioni che partono da condizioni iniziali diverse fra di loro (il quanto e come siano diverse è un problema tuttora aperto e dibattuto che illustrerò in seguito). Il fatto di considerare più stati iniziali simili, ma diversi, permette di tenere conto dell’incertezza da cui parte la previsione, cioè l’approssimazione con cui conosciamo lo stato attuale dell’atmosfera. Per essere chiaro: possiamo avere quante stazioni di misura vogliamo sparse sulla superficie terrestre e oceanica che ci danno informazioni sulle grandezze meteorologiche (pressione, temperatura, umidità, ecc.), ma per quante misurazioni possano esserci, non avremo mai una copertura completa e continua dell’atmosfera e quindi possiamo conoscere la situazione attuale dell’atmosfera stessa solo con una certa approssimazione.
Ma andiamo con ordine. La prima operazione da fare è comunque determinare l’analisi, cioè lo stato attuale dell’atmosfera da cui le previsioni devono partire. Per determinare questo stato iniziale si fa uso di tutte le misure esistenti, dai satelliti alle stazioni al suolo, dalle navi agli aerei, dai radiosondaggi ai radar e attraverso un modello numerico meteorologico e complicate operazioni matematiche le si mettono tutte assieme in modo coerente, nel rispetto dei bilanci fisici e termodinamici dell’atmosfera. Questa è una delle operazioni che viene svolta dal Centro Europeo di Reading in Inghilterra, noto come ECMWF (European Center for Medium-range Weather Forecast). Una volta ottenuta l’analisi essa viene inviata ai vari servizi meteorologici che la utilizzeranno per fare previsioni a breve termine con i loro modelli ad alta risoluzione (es. il BOLAM al servizio meteorologico regionale della Liguria, ma lo stesso vale anche per i servizi negli altri stati europei, come nel caso dell’HIRLAM nel nord Europa).
Nei centri in cui sono disponibili grosse risorse di calcolo, come il Centro Europeo stesso o l’NCEP negli Stai Uniti, vengono invece fatte le “ensemble forecast” di cui il risultato più noto ai fini pratici della previsione meteorologica sono gli “spaghetti”.
Abbiamo detto che bisogna generare diversi stati iniziali simili all’analisi iniziale per poter poi fare diverse previsioni che compongono l’ensemble. Date le misure a nostra disposizione, potremmo avere infiniti stati iniziali possibili coerenti con le misure, che differiscono l’uno dall’altro di pochissimo. La situazione ottimale sarebbe quindi quella di fare un numero infinito di previsioni partendo da tutte queste condizioni iniziali per avere la casistica completa di ciò che potrà succedere. Ovviamente questo non è possibile e quello che bisogna quindi fare è introdurre perturbazioni (numeriche) ottimali per ottenere almeno le condizioni iniziali più “rappresentative”. In altre parole le perturbazioni migliori sono quelle che generano gli stati iniziali che evolveranno in modo più differente possibile nel tempo. In questo modo si può ottenere un ampio spettro di possibilità future (è stato dimostrato che perturbare lo stato iniziale in modo casuale può facilmente portare ad un peggioramento dei risultati, quindi la faccenda non è poi così semplice).
I due metodi che attualmente sono impiegati per generare gli stati iniziali sono noti come Singular Vectors e Breeding. Il primo è utilizzato al ECMWF, il secondo al NCEP. Esistono ragioni a favore e contro ognuno dei due metodi e neanche a dirlo ognuno dei due centri di ricerca è assolutamente orgoglioso e a favore del proprio. Semplificando molto, se da un lato il metodo dei Singular Vectors è al momento supportato da una più solida teoria matematica, il Breeding risulta essere concettualmente più semplice e richiede risorse di calcolo notevolmente inferiori. L’effettiva bontà è oggetto di studio e solo il tempo ci darà risposta. Non entro nei dettagli dei metodi perché ciò necessiterebbe una laboriosa (e noiosa!?) trattazione matematica.
Veniamo invece ai prodotti delle ensemble forecast. Una volta che in un dato giorno vengono generate le varie condizioni iniziali e vengono fatte tutte le previsioni (per avere un ordine di grandezza si parla di 50 previsioni) i risultati sono i seguenti:
1) Media dell’ensemble
La media delle previsioni per un dato istante permette di fornire una previsione che è più accurata di ogni singola previsione dell’ensemble (la media agisce come un filtro sugli errori). In questo caso noi utenti avremo mappe dei campi meteorologici in quota o al suolo ottenuti mettendo insieme tutte le previsioni dell’ensemble.
Inoltre si hanno comunque a disposizione un vasto numero di singole previsioni le quali possono mostrare possibili scenari futuri di cui tenere conto. Ad esempio si può verificare che una depressione apparentemente innocua possa evolvere, in alcune o poche previsioni, in un pericoloso ciclone. In questi casi l’evoluzione viene tenuta sotto controllo con particolare attenzione.
2) Dispersione dell’ensemble (SPAGHETTI PLOT)
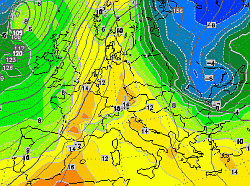
A seconda di quanto le previsioni per un certo giorno si discostano l’una dall’altra, è possibile avere una valutazione della predicibilità. In altre parole si ottiene una misura dell’affidabilità della previsione. Questa è l’informazione che si ottiene dagli “spaghetti”. In queste carte ogni singola linea colorata tracciata rappresenta la previsione di un membro dell’ensemble (membro dell’ensemble = singola previsione).
Esistono due carte tipiche di spaghetti. Ci sono mappe di altezza geopotenziale sulla superficie isobarica (a pressione costante) 500 hPa (mbar). Oppure viene mostrata la temperatura alla 850 hPa. Per ogni previsione (ogni linea colorata) vengono mostrati solo 3 valori standard del campo per motivi di leggibilità della carta. Del resto la lettura della stessa non differisce dalle consuete carte meteorologiche: sono mostrate alte e base pressioni, o zone fredde e calde nel caso della T a 850hPa, ma in più viene data l’informazione sulla attendibilità.
Più le linee sono lontane, più l’attendibilità della previsione è bassa. Ovviamente le linee sono inizialmente vicine e con il trascorrere del tempo divergono per arrivare a situazioni “disastrose” che indicano una previsione poco affidabile.


{kind=link}